

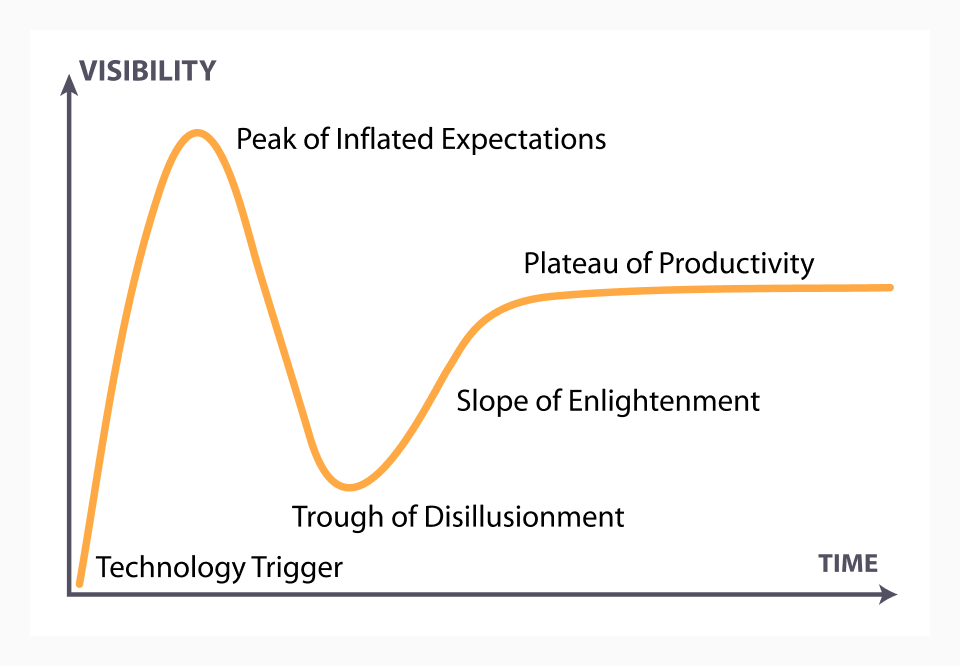
Every time a relevant new technology comes along, breaking paradigms and bringing innovation, many people think it is the solver of all problems. We start to hear things like: “no more need for y,” or “why are you still doing x if we have z.” Every time, same patterns. Some examples: Docker for containers, Kubernetes for orchestration, Lambda for FAAS, and then the service mesh. For those of you who are still at the peak of expectations, here are ten tips that will make surfing the trough of disillusionment easier.
1. Distributed systems won’t get easier
People think that the service mesh will make their life easier; with all the stuff it takes care of, there is no need for x, y, or z. The service mesh is one more complex system in your chain, and you have to make it as strong as all the other systems. However, you should not be inattentive to the parts the infrastructure handles now at the application level.
2. Double the links in your chain
Are you worried about the number of network calls and failure modes your systems currently have? Double this number: welcome to the service mesh. Every application has a proxy sidecar that controls all the traffic flowing in and out of your app. This communication is done via loopback of the containers, but we are still talking network. Besides, if you are not using a managed service, you manage a control plane that is especially critical for your whole infrastructure.
3. The 12 factors are now mandatory
If you are deploying your application to EC2 instances, missing most of the 12-factor app features won’t hurt you a lot. The slow pace of spinning up a whole instance will compensate for your application not being very responsive to boot time, shutdowns, etc. Going to Kubernetes, they become more sensitive, but missing a few of them is still acceptable. In the service mesh, miss one or two factors, and your systems misbehave.
4. The 12 factors are now 20 factors
The 12-factor app is terrific, but things have changed quite a bit since its creation, so only 12 factors are not enough anymore. There is no mention of critical items for this kind of deployment. Elements such as health checks, liveness probes, readiness probes, and instrumentation, to name a few, are essential for your application to be able to run on a service mesh.
5. Instrumentation is not gone
If you are used to bashing into your app and checking the connection to external services: forget it. Now you are talking to a sidecar/proxy that will always answer to you. You need enough instrumentation in your app to check everything from the outside; checking things inside is almost impossible. Accessing instances to check on application health/status is an anti-pattern, so you better fix that before starting to think about service mesh.
6. The intelligent network won’t do your work
You need even more code than before instrumenting your code to take full advantage of the service mesh features. The context of a request needs to be propagated through the mesh (using headers if using HTTP) to trace a call successfully. Besides, the standard view is pretty poor. You probably need a better insight into your app than the time of network calls, which is what you get by default.
7. Forget the beautiful graphics you saw in demos
Did you get amazed by the beautiful graphics shown in demos and talks from Istio and other solutions? Well, be ready to add a couple more links to your chain to use that, and apply an anti-pattern, which is running monitoring along with your own systems. If you are serious about running it in production, be ready to partner with a vendor that integrates well with the solution of choice or be prepared to do some work to use it reliably.
8. Not everybody needs a Service Mesh
This one seems obvious, but I think it is worth mentioning: does your application run fine using less than three computer instances? Good news: you probably don’t need a service mesh. The complexity of adopting the service mesh will likely outweigh its benefits. You would be better off effectively instrumenting your application and simplifying the infrastructure layer.
9. A service mesh is not the only way
Many companies have been using features provided by the service mesh for many years now, even though the concept only emerged a couple of years ago. How? You can implement everything you get from a mesh in other ways by using different tools. Some examples: canary releases – feature flags; fault injection – chaos engineering tools; tracing – open tracing, and so on.
10. Don’t give up!
If you are still reading this, you must be really interested in using a service mesh solution. Don’t be scared off by all these points. These are some tips to make your journey easier. There are plenty of good points about adopting such a solution, and they are well documented. We are only exploring some of the downsides here.







